Des ordinateurs sur roues. C'est ainsi que les gens voient actuellement les
voitures. Pratiquement tout ce qui se passe dans un véhicule est contrôlé et actionné par un microcontrôleur, de l'ouverture des fenêtres au calcul du mélange air-carburant optimal pour la demande de couple actuelle. Mais la puissance de calcul qui fait son chemin dans les véhicules n'est qu'à peine effleurée.
Augmentation des véhicules autonomes L3 et robotaxisL'ère du transport autonome est en train de s'ouvrir et, avec elle, une nouvelle ère d'exigences informatiques pour l'industrie
automobile. Les
voitures automatisées nécessitent de vastes ensembles de capteurs pour analyser l'environnement et fournir à la
voiture les données dont elle a besoin pour imiter la conduite humaine. Le rapport "Voitures autonomes, robotaxis et capteurs 2024-2044" d'IDTechEx a révélé que les principaux robotaxis de niveau 4 de la
SAE possèdent jusqu'à 40 capteurs individuels. Combiné au déploiement prochain de technologies automatisées sur le marché des véhicules, ce phénomène entraînera un TCAC ((taux de croissance annuel composé) de 13 % sur 10 ans pour le marché des capteurs
automobiles. Cependant, les capteurs seuls sont pratiquement inutiles sans un système informatique de haute performance qui traite leurs données et construit un rendu 3D de l'environnement pour informer la politique de conduite programmée du véhicule.
Le calcul de haute performance (HPC) prend les données en temps réel issues de la batterie de capteurs et effectue plusieurs traitements importants. Les deux principaux défis auxquels il est confronté sont la
fusion des capteurs et la classification des objets, et les
avis divergent quant à l'ordre dans lequel ces opérations doivent être effectuées. Certains pensent qu'il est préférable de procéder à une fusion précoce, dans laquelle toutes les données des capteurs sont combinées en un rendu 3D de la scène, puis un algorithme d'intelligence artificielle, exécuté par l'unité HPC du véhicule, identifie et étiquette chaque objet détecté. D'autres pensent qu'il faut générer une liste d'objets à partir de chaque capteur, puis fusionner les résultats. Cette méthode présente l'avantage de pouvoir croiser les détections de chaque capteur et de vérifier leur concordance. L'inconvénient de cette méthode est qu'il est difficile de gérer les divergences entre les listes d'objets provenant de différents capteurs.
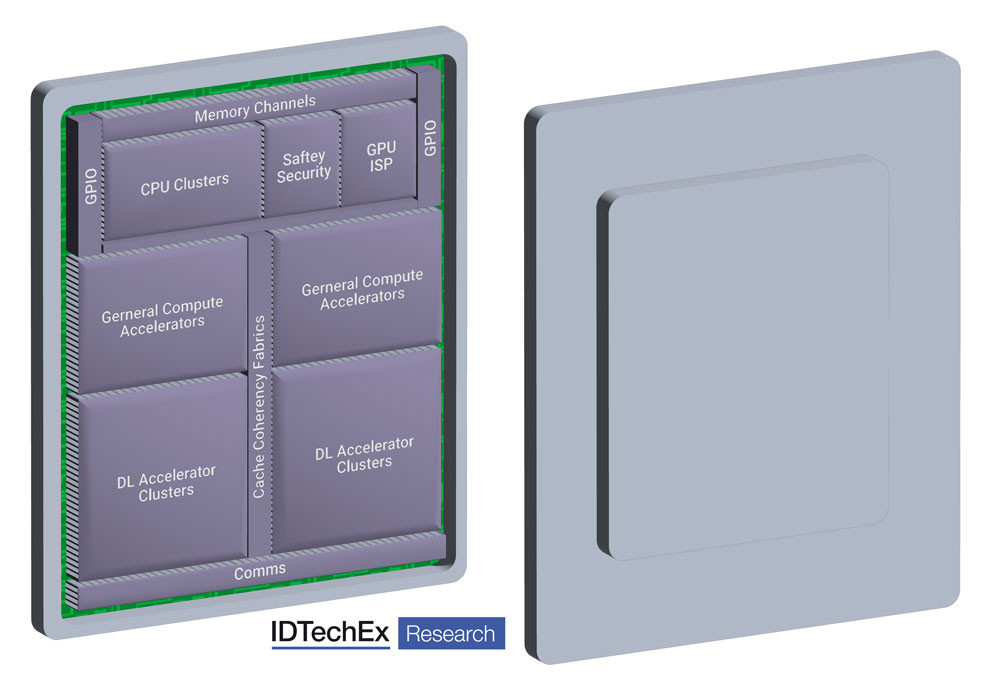
Le SOC (SOC= des puces uniques) autonomeQu'il s'agisse de fusion tardive ou de fusion précoce, le calculateur de haute performance aura toujours beaucoup de données à traiter sous la forme de traitement d'images et d'exécution d'algorithmes d'intelligence artificielle pour la classification d'images et la politique de conduite. Les composants clés qui gèrent ces tâches sont les processeurs graphiques (GPU), les processeurs de calcul (CPU) et la mémoire vive. En règle générale, il s'agit de composants distincts ; toutefois, les exigences spécifiques du calcul de haute performance pour les
voitures autonomes ont conduit à les combiner sur des puces uniques appelées SOC ou systèmes sur puce. Ces systèmes combinent les GPU, les CPU, la RAM et d'autres éléments sur un seul morceau de silicium. Le SOC idéal peut recevoir les données de tous les capteurs de
conduite autonome du véhicule, les traiter, identifier et classer tous les objets détectés et créer un ensemble d'actions de direction, d'accélération et de freinage en fonction de la politique de conduite. Le SOC est donc responsable de l'ensemble du système de conduite autonome.
Il est essentiel de réunir toutes ces
caractéristiques sur une seule puce pour répondre aux exigences de calcul de la conduite autonome. Avec une séparation physique quasi nulle, chaque partie de la puce peut échanger des données avec un temps de latence proche de zéro, un bruit quasi nul et une bande passante très large. Cela s'oppose à l'utilisation de composants discrets répartis sur une carte de circuit imprimé, avec plus d'interfaces et plus de traces de données introduisant du bruit et de la latence.
Les GPU sont un élément clé du puzzle ; leurs capacités de traitement d'images, combinées à leur aptitude à exécuter des algorithmes d'IA par le biais de l'apprentissage en profondeur et des réseaux neuronaux, en font une pierre angulaire du SOC. C'est pourquoi nous voyons Nvidia gagner du terrain dans le domaine des véhicules autonomes. Nvidia a une longue histoire de développement de GPU pour les applications graphiques en informatique et a été capable de pivoter, en apportant son expertise à l'industrie automobile. Ses plateformes Xavier et Orin ont été des éléments essentiels du traitement informatique des véhicules autonomes.
Mobileye est une autre entreprise pionnière dans ce secteur. Fondée en 1999, elle s'est rapidement imposée et s'est fait un nom, suscitant l'intérêt d'Intel et conduisant à son acquisition. Elle est aujourd'hui à nouveau cotée en bourse et a trouvé sa place dans de nombreux véhicules grand public équipés d'applications ADAS.
Mobileye et Nvidia ont récemment augmenté leur puissance de calcul, passant de quelques TOPS (terra operations per second) à des dizaines de TOPS, puis à des centaines de TOPS et enfin à des milliers de TOPS. Ces améliorations sont principalement dues à l'adoption de nœuds de plus en plus petits par des fonderies de premier plan telles que TSMC et Samsung. Ils ont cherché à obtenir ces améliorations par le biais de technologies de nœuds plus petits dans les fonderies qui les soutiennent.
Développement des technologies des semi-conducteursCes dernières années, IDTechEx a vu Mobileye, Nivida et d'autres passer de 28 nm en 2018 à des solutions FinFET de 7 nm et moins en 2021. Cependant, les fonderies produisent maintenant des technologies inférieures à 5 nm et se dirigent vers des technologies inférieures à 1 nm à l'avenir. IDTechEx a constaté que chaque fois que le nœud technologique est divisé par deux, la puissance de calcul augmente d'un facteur 10. Mais la recherche de nœuds de plus en plus petits deviendra de plus en plus coûteuse. Une plaquette de 300 mm de la technologie 3 nm de TSMC (Taiwan Semiconductor Manufacturing Company) coûte environ 20 000 USD, et ce
prix continuera d'augmenter à mesure que les technologies inférieures à 3 nm seront demandées dans divers secteurs, depuis les applications informatiques normales telles que les téléphones, les ordinateurs portables et les PC, jusqu'à la nouvelle demande émanant du secteur de l'automobile.
En tant que tels, les développeurs HPC automobiles doivent réfléchir à la manière dont ils peuvent optimiser les technologies existantes pour obtenir les meilleures
performances. L'une des approches observées consiste à mettre davantage l'accent sur l'intelligence artificielle (IA), les réseaux neuronaux (NN) et les accélérateurs d'apprentissage profond (DL). Ceux-ci utilisent de nouvelles stratégies de traitement des données améliorées par l'IA, réduisant la dépendance aux approches classiques trouvées dans le GPU. Cela permet d'augmenter les performances de la puce à moindre
coût, ce qui nécessite moins d'investissements dans les technologies de nœuds plus petits et produit même un avantage en termes d'efficacité globale. L'IA devient de plus en plus courante dans les schémas fonctionnels des SOC des principaux acteurs de niveau 2 tels que Mobileye et Renesas. Mais une perspective particulièrement intéressante est celle de Recogni. Recogni est une start-up qui a mis au point un accélérateur d'IA pour les applications SOC de conduite autonome qui promet une puissance de calcul et une efficacité qui changent la donne.
Malgré la réduction de la taille des nœuds et les solutions imaginatives en matière d'intelligence artificielle, l'industrie des puces informatiques dans son ensemble continue de voir son rythme de développement ralentir. La loi de Moore stipule que la puissance de calcul devrait doubler tous les deux ans, une formule empirique vieille de plusieurs décennies qui s'est maintenue jusqu'à récemment. Certains affirment que la loi de Moore commence à ralentir car l'industrie est confrontée à des défis technologiques de plus en plus difficiles à relever pour réaliser des gains incrémentaux de plus en plus faibles. D'autres affirment que la loi de Moore est morte.
Le concept des "chiplets" est une solution de premier plan pour faire face au ralentissement de la loi de Moore et à l'augmentation substantielle du coût de fabrication des circuits intégrés monolithiques (CI). Le concept de base des chiplets consiste à déconstruire un circuit intégré monolithique en blocs fonctionnels distincts, à transformer ces blocs en chiplets séparés, puis à les réassembler au niveau de l'emballage. L'objectif ultime d'un processeur basé sur les chiplets est de maintenir ou d'améliorer les performances tout en réduisant les coûts de production globaux par rapport aux circuits intégrés monolithiques traditionnels. L'efficacité de la conception des chiplets dépend fortement des techniques de conditionnement, en particulier celles utilisées pour interconnecter plusieurs chiplets, car elles ont un impact significatif sur les performances globales du système. Ces technologies avancées de conditionnement des semi-conducteurs, qui englobent des approches telles que les circuits intégrés 2,5D, les circuits intégrés 3D et le conditionnement en éventail à haute densité au niveau de la plaquette, sont collectivement désignées sous le nom de "conditionnement avancé des semi-conducteurs". Ces techniques de pointe facilitent la convergence de multiples chiplets, souvent produites à différents nœuds de processus, sur un seul substrat. Cette convergence est rendue possible par l'utilisation de bosses de taille compacte, ce qui permet d'augmenter les densités d'interconnexion et d'améliorer les capacités d'intégration.
Si l'on considère le paysage actuel des technologies avancées de conditionnement des semi-conducteurs dans l'industrie, prenons l'exemple du secteur des unités centrales de serveurs. Alors que la plupart des unités centrales de serveurs contemporaines sont construites autour de systèmes sur puce (SoC) monolithiques, des développements notables sont apparus. En 2021, Intel a annoncé son prochain processeur serveur, Sapphire Rapids, qui adoptera une nouvelle approche. Ce processeur de nouvelle génération sera constitué d'un module de quatre puces interconnectées via le pont EMIB (Embedded Multi-die Interconnect Bridge) d'Intel, ce qui représente une solution de conditionnement avancée des semi-conducteurs en 2,5D.
Parallèlement, AMD a exploité la puissance des techniques avancées de conditionnement des semi-conducteurs en 3D pour améliorer les performances des unités centrales de serveurs. Dans le cas de son dernier processeur serveur, Milan-X (sorti en mars 2022), AMD utilise une stratégie d'emballage 3D qui implique l'empilement d'une matrice de cache directement sur le processeur. Selon AMD, cette innovation permet de multiplier par 200 la densité d'interconnexion par rapport à l'emballage 2D conventionnel. Ces développements ne se limitent pas aux seuls processeurs ; le domaine des centres de données a également été témoin de l'intégration de technologies avancées de conditionnement des semi-conducteurs pour d'autres composants, tels que les accélérateurs. NVIDIA, un acteur clé, utilise depuis 2016 la technologie d'emballage 2,5D de TSMC, connue sous le nom de Chip on Wafer on Substrate (CoWoS), pour ses accélérateurs GPU haut de gamme.
Cette vague d'adoption, illustrée par Intel et AMD dans leurs produits de pointe, indique une utilisation croissante des technologies avancées de conditionnement des semi-conducteurs dans l'ensemble de l'industrie. Cette tendance va au-delà des unités centrales de serveurs et englobe toute une série de composants de centres de données. À mesure que le paysage industriel évolue, ces méthodologies d'emballage innovantes sont appelées à jouer un rôle central dans l'amélioration des performances, de l'intégration et de l'efficacité.
Dans un avenir prévisible (sur une période de 10 à 15 ans), poussé par des exigences de traitement croissantes et la nécessité d'une bande passante importante pour une
consommation d'énergie minimale, le secteur automobile suivra une trajectoire semblable à celle du marché de l'informatique en nuage et de l'informatique à haute performance (HPC). Cette trajectoire implique l'intégration de divers éléments de propriété intellectuelle (IP) et de silicium au niveau du boîtier afin d'obtenir des caractéristiques essentielles et des performances optimales. Dans le contexte des processeurs informatiques pour véhicules autonomes, le paysage de l'emballage verra l'amalgame de multiples composants en silicium dans le même emballage, mettant en œuvre des approches de conception avancées en 2,5D et en 3D.
La demande croissante de calcul à haute performance dans les véhicules et la nécessité d'une croissance continue des performances entraîneront une évolution rapide de la technologie utilisée dans les ordinateurs automobiles. La taille des nœuds inférieurs à 3 nm, la conception des chiplets, le recours accru à l'accélération de l'IA, l'emballage 2,5D et même l'emballage 3D deviendront tous des éléments normaux du calcul de haute performance pour les technologies autonomes dans les voitures. Les ordinateurs sont présents dans les voitures depuis des décennies, mais les technologies à venir feront passer une voiture moyenne d'aujourd'hui pour une technologie de ligne fixe dans un monde de smartphones.
Source : IDTechEx
Auteurs : Dr James Jeffs, analyste technologique principal à IDTechEx, Dr Yu-Han Chang, analyste technologique principal à IDTechEx
Dr James Jeffs, analyste technologique principal à IDTechEx, Dr Yu-Han Chang, analyste technologique principal à IDTechEx, écrit le 20/12/2023































 Newsletter
Newsletter